評估動物實驗樣本數之基礎原理介紹
張鐳耀 博士
樂斯科生物科技(股)公司
適當的動物試驗樣本數,關係到是否能獲得足夠的試驗數據,並足以進行有效的分析,過低的動物數目將無法提供足夠的資訊去分辨試驗效果,而過多的動物數目亦無助於提高試驗的可信度與準確性,適當的動物數量,有助於合乎科學與試驗倫理的需要,尤其現今動物試驗管理提倡3Rs精神與IACUC功能的彰顯,合適動物使用數量更是需要重視的部分,由於動物試驗的模式眾多,採取的實驗設計與統計法基礎皆不同,皆會影響動物樣本數的決定法,因此文中僅淺略介紹決定動物數量的基本概念與方法。
動物試驗涵蓋領域廣泛,樣本數會因使用目的不同而有所差異,在使用目的方面,包含從動物模式開發、法規中各類規範性動物試驗、各類「探索性研究」(exploratory study)和「確認性研究」(confirmatory study)等,其樣本數計算的依據與方法皆不相同,本文將著重在「確認性研究」與探索性研究」中連續性資料的樣本數估算概念介紹。首先介紹「確認性研究」,其基礎即是假說檢定(Hypothesis Testing),進行可管控與可測量的試驗,其樣本數估算基於統計原理,包含信賴區間(Confidence Interval)、Type I error(a),也就是P值(P-Value)、效應大小,又稱效果量(Effect Size)、標準偏差(Standard Deviation)與Type 2 error(b)和與其相對的就是檢定力(Power, 1-b),在利用統計方式計算樣本數之前,研究人員可藉由文獻探討(Reference review)獲得計算樣本數所需的各項參數,協助研究人員計算正式實驗時所需的動物樣本數,如無其它文獻可供參考,則需要借重前導研究(Pilot Study)來獲得所需要的參數,而這類型的研究即為探索性研究。
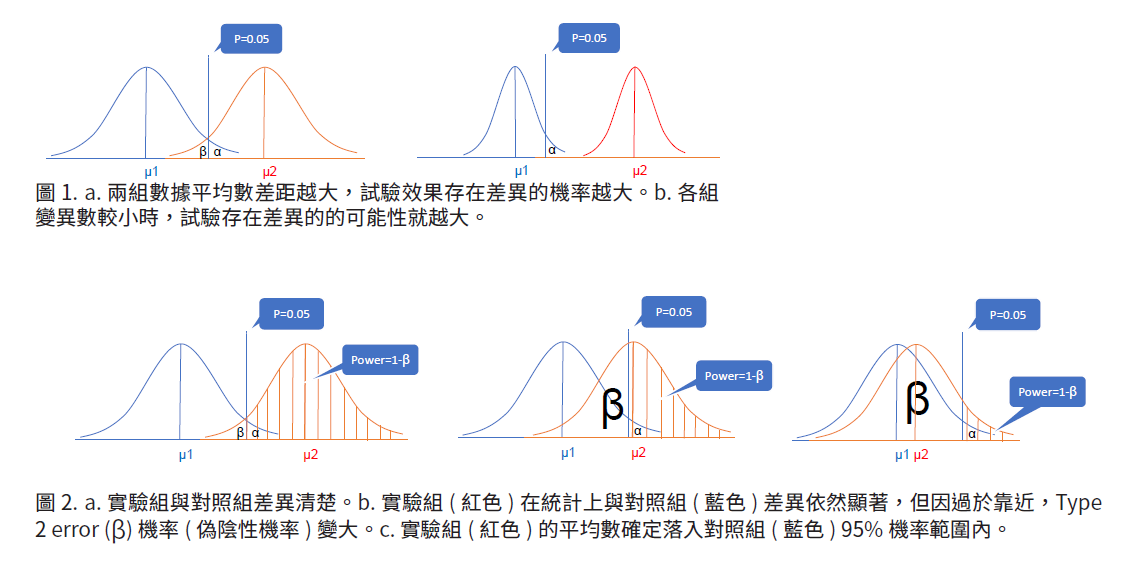
如何計算樣本數?以連續性資料如體重、血壓…等等為例,當實驗組與對照組的平均數的差值越大,試驗項目產生的效果越有可能為真,當每組數據的離散程度越小(變異數越小),兩組的的差異越可能為真(圖1),統計分析習慣將顯著差異設在P-value=0.05,換句話說,實驗組的平均數如果落入對照組的5%的區域,即表示兩組之間的差異有5%機率是非真。當每組的離散程度越大,且實驗組的平均數又與對照組的平均數接近時,實驗組的平均數落入對照組的95%區域內的可能性就會被提高,換句話說偽陰性機率被提高(圖2),因此適度的降低組內離散程度不僅獲得較可信數據,並可以藉由信賴區間的概念,換算出所需的樣本數。
從下方的信賴區間公式1可了解當變異數s越大,離散程度也越大,同時也可以藉由適當的提高樣本數(n),來達成降低離散的目的,因此可利用設定的P-value換算出Z-Score值(標準化值/Z分數),經公式2的Z-score的反算,在已知變異數(s)的條件下,即得知所需的樣本數(n)(公式3.1),此方式即基礎的樣本數計算方法。
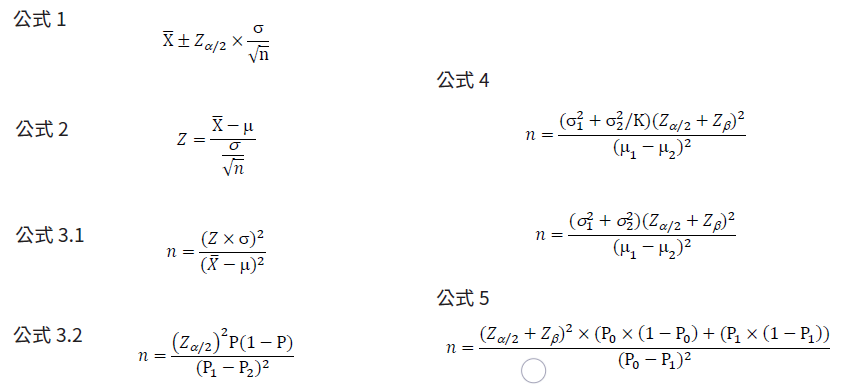
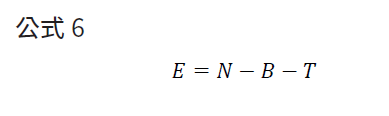
舉例說明: 當實驗組平均收縮壓為140毫米汞柱(),對照組的平均收縮壓在125毫米汞柱(m),標準偏差(s)為20,P-value設為0.05,其Z-Score即為1.96,換言之,實驗組與對照組的差值經過標準化後必須大於1.96才表示在統計上有顯著的差異,因此經過反算得n值至少需要7隻/每組,比例型資料的樣本數計算,請參考公式3.2。
上述的計算又稱Precision-based模式,可用在單一樣本試驗,但此類研究方式有兩項不足之處,第一點:上述方式只考慮了Type I error(a),也就是P-value偽陽性的機率,並沒有考慮Type II error(b),也就是偽陰性的機率,當兩組數值分佈很接近時,即使得到差異顯著的結論,但同時偽陰性(Type II error)的機率也大增(圖2.b),因此為了獲得較為可信的統計數據,除了設定P-value外,設定統計檢定力Power(1-b)亦是獲得可信試驗結果的關鍵,通常生醫研究將偽陰性設定在0.2(即20%機率),統計檢定力即為0.8(即80%機率),針對不同的研究可提高統計檢定力的機率設定。第二點:上述的統計原理是基於實驗組與對照組擁有相同的變異數的條件下,但實際的生醫研究中,組間通常不會有相同變異數,因此在考量統計檢定力與變異數兩個因子後,可使用以下的公式進行連續型與比例型數據的樣本數估算,此種方法稱作Power-based模式。
舉例說明,同樣使用血壓研究的例子,假設兩組變異數分別為18與20毫米汞柱,另外設定power為80%,K值為兩組間的樣本數比例,如實驗設計中兩組樣本數設定相同,則K值為1,以此公式4帶入相關數據後可得每組的樣本數最少需要25隻動物,因此當考量統計檢定力時(power),樣本數會增加,但同時也會提高實驗的準確性,降低動物試驗的不準確性,避免整體動物的使用浪費,從長遠與生醫研究的角度看,好的試驗設計加上適當實驗動物數量,更加符合3Rs的精神,而比例型資料的樣本數計算,請參考公式5。
上述不論是Precision-based模式或是Power-based模式,皆需要預期的參數,這些參數可以藉由已發表資料中獲取,但無相關數值時,則需要進行前導試驗獲得所需參數,但該如何設定前導試驗中每組的動物使用隻數呢? Resource equation method可做為前導試驗中動物樣本數計算的方式(公式6),此方式是基於對誤差自由度(E)的最低接受數值,Mead(1998)總結出E落在10~20之間,能獲得較為合理的變異數。
舉例說明,假設試驗為2 X 4 因子設計(factorial design),試驗分為對照組與實驗組2組,並分別在4個不同環境溫度下進行,每組所需的動物隻數,假設先主觀設定3隻,此每組動物隻數是否合理可使用Resource equation method進行判斷,N(總隻數的自由度)=23 [(2組X 3隻X 4種環境溫度)-1],B(區集數的自由度)=0(此範例無區集),T(試驗組數的自由度)=7 [(2組X 4種環境溫度)-1],因此可得E=23-0-7=16,因此每組使用3隻動物進行試驗即為一個相對合理的數字,並且研究人員可以參考此方式,經由設定E值為20或10,來獲得試驗每組至多與至少的動物數量,但Resource equation method的本質依然是簡略的模式,會產生較高的偽陰性,因此只適合作為前導試驗使用,此方式利用在其它實驗類型的方式,可參閱其它文獻範例(Arifin等, 2017),而正式大型試驗還是需要以較為完備的統計方式獲得樣本數估算。其它常見的估算模式還包含Cohen’s d或稱signal/noise等方式,其基本原理與上述介紹的統計方式相同,可藉由現有的表格帶入數值獲得所需的動物樣本數,其方法可參考以下網站(http://www.3rs-reduction.co.uk/html/6__power_and_sample_size.html)。
進行動物試驗時,有時會產生動物耗損,為了避免因為試驗中動物耗損或失敗,導致後續分析時動物數量不足的問題,研究人員需將耗損率/失敗率納入計算,例如:經由計算後得到每組需10隻動物,但同時知道此類型研究的動物耗損可能達20%,則需將耗損量納入計算,因此每組的動物數量即需13隻(100.8)。統計的樣本估算的準確度是基於熟練且穩定的技術操作、良好且恆定的飼養環境、優異的實驗設計、以及高品質的實驗動物,才能降低變異與穩定變異,才能讓樣本數的估算發揮應有的價值,進而獲得有意義的生醫研究成果。
參考文獻
- Arifin, Wan Nor & Wan Mohammad, Wan Mohd Zahiruddin. (2017). Sample Size Calculation in Animal Studies Using Resource Equation Approach. Malaysian Journal of Medical Sciences. 24. 101-105. 10.21315/mjms2017.24.5.11.
- Mead, R. (1988). The design of experiments: Statistical principles for practical applications. Cambridge University Press.